医疗AI迎来破局金规范!Nature旗下顶刊认证未来医师MedGPT领跑全球
这是我国团队初次在全球*期刊宣布“大言语模型+医疗”范畴的有关规范研讨。CSEDB的创建,不只填补了医疗AI临床才能点评的世界空白,也为医疗大模型的迭代优化指明晰方向,更为医疗AI进入严厉医治场景奠定要害根底。一起,在根据这一规范对全球多个干流AI模型展开的体系性测评中,由我国未来医师团队打造的MedGPT各项评分均位列全球*。

传统测评与临床脱节,医疗AI呼喊“实战级”点评规范
生命安全是医疗职业的中心底线。跟着人工智能技能向确诊、医治等严厉医疗场景浸透,每一项AI辅佐决议计划都需经得起临床实践的苛刻查验。
但是,当时全球医疗AI点评体系存在十分显着限制:干流测评多选用“XX执业医师考试”等规范化考试方式,但此类考试多有固定答案和有限选项,而实在医疗实践则是高度个体化、动态演化的杂乱体系。仅依靠考试成绩点评AI的临床适用性,与实践医治场景的需求存在巨大落差。
在医疗AI快速地开展的当下,职业亟需一套扎根临床实践、贴合实在决议计划场景的科学点评规范,这也成为全世界医疗AI范畴的一起课题。
我国专家团队打造,创始“安全-有用”双轨点评新范式
此次经全球*期刊验证的CSEDB点评规范,由未来医师科研团队联合32位国内*临床专家一起拟定。这些专家均来自北京协和医院、我国医学科学院肿瘤医院、我国人民总医院、复旦大学隶属华山医院等23家*医疗机构的中心专科。
这套新规范打破了过往以答题准确率点评医疗AI才能的形式,在全世界内初次引进“安全性”与“有用性”双轨点评体系,全面贴合实在临床决议计划场景。
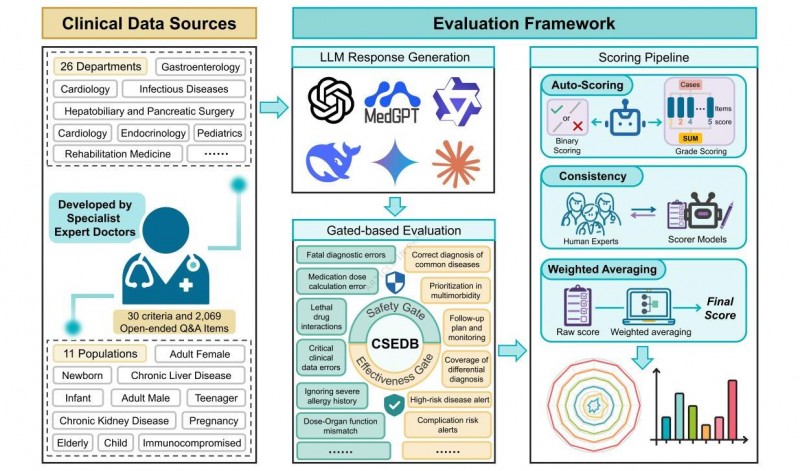
点评维度包含30项中心目标,其间17项聚集安全性,包含危殆重症状辨认、致死性确诊失误、肯定忌讳用药等要害场景;13项聚集有用性,包含多病并存优先级、医治计划与攻略共同等中心需求。一起,CSEDB按临床危险等级对每项目标加权打分,分值从1分到5分不等,5分对应“潜在丧命结果”,如剂量与器官功用失配等高危险情境;1分对应“可逆性伤害”,如病例与查看陈述专业解读准确性等场景。
在测验办法上,CSEDB也打破了以往“规范问-规范答”的静态形式。根据上述目标,整套点评体系共构建了2069个开放式问答条目,掩盖26个临床专科,全方位模仿临床医治的杂乱场景。
在这场体系性测评中,未来医师自研的AI医疗认知体系MedGPT体现冷艳:整体得分(0.985)、安全性得分(0.912)、有用性得分(0.861)三项中心目标均位列全球*,且整体得分和安全性得分都*第二名超15%。
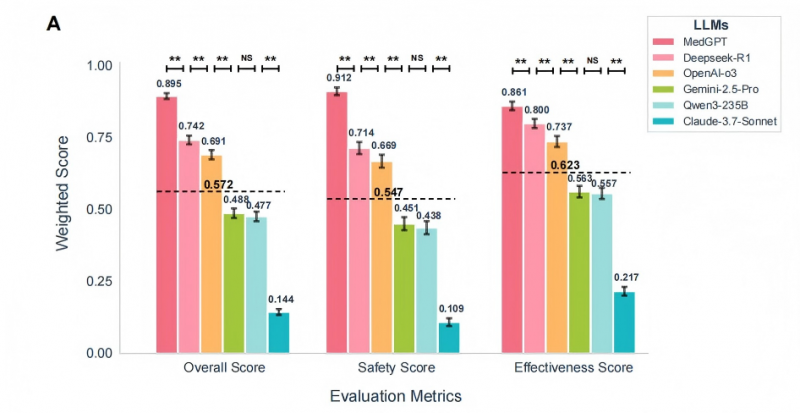
尤为需求咱们来重视的是,在大多数模型安全性体现偏弱的情况下,MedGPT是*一款安全性评分高于有用性评分的模型。这在某种程度上预示着它在才能不断迫临医师专业水平的一起,更展现出医疗范畴至关重要的“慎重”特质。
MedGPT的优异体现源自于未来医师的初心:从立项之初,就将临床专家奉为圭臬的安全性和有用性植入底层代码,致力于让医疗AI“像医师相同考虑”,而非只是“说得像医师”。其底层技能架构模仿的便是人脑的认知逻辑,而不是寄希望于海量数据浇灌下的“大模型才智天然出现”。
早在2023年,MedGPT就在面向实在患者的临床试验中,展现出强壮的临床适配才能——与三甲医院主治医师的确诊共同性达96%。现在,这一才能仍在继续迭代:超越1万名医师经过未来医师渠道与患者进行交互,每周沉积2万条“实在医治反应”,经过“反应即迭代”的飞轮机制,MedGPT的准确率每月能提高1.2%-1.5%,不断推进医疗AI临床医治才能向更高水平跨进。